
In the world of data integration and streaming, Kafka has established itself as a leading platform. It is an efficient and scalable solution for handling real-time data streams. Kafka Connect, a key component of the Kafka ecosystem, allows users to easily integrate data from different sources and sinks. But what exactly is a Kafka Connector? Simply put, a Kafka Connector is a plugin that extends the functionality of Kafka Connect by enabling the seamless integration of data with external systems. It acts as a bridge between Kafka and various data storage systems, databases, and other data processing frameworks. Through these connectors, users can reliably and efficiently stream data to and from Kafka, making it an indispensable tool for building robust and scalable data pipelines. In this article, we’ll explore the concept of Kafka connectors in more detail and dive into the different types, use cases, and benefits they offer.
Inside This Article
- Overview
- Understanding Kafka Connect
- Kafka Connect Connectors
- Common Use Cases for Kafka Connect
- Conclusion
- FAQs
Overview
When it comes to managing data in real-time, Kafka Connect plays a critical role in the Kafka ecosystem. Kafka Connect is a framework and ecosystem that enables efficient and scalable data integration between external systems and Apache Kafka. With Kafka Connect, organizations can easily connect and transfer data to and from various sources, making it an essential tool for data engineers and developers.
Designed as a lightweight and distributed system, Kafka Connect provides a scalable and fault-tolerant solution for data integration. It operates as a connector-based framework, where connectors act as plugins that enable data movement between Kafka and external systems. These connectors are responsible for defining how data should be sourced or sinked from and to Kafka.
One of the key advantages of Kafka Connect is its ease of use and extensibility. With a simple and intuitive configuration, developers can easily define the necessary connectors and mappings to connect Kafka with other systems. Kafka Connect also provides built-in support for distributed mode, allowing for a high level of scalability and reliability.
Moreover, Kafka Connect offers a wide range of connectors that cater to various use cases. Whether it’s integrating with databases, cloud storage, messaging systems, or any other data source or sink, Kafka Connect has a connector to streamline the process. These connectors provide seamless integration and handle tasks such as data schema management, data conversion, and error handling.
Overall, Kafka Connect simplifies the data integration process by providing a standardized and scalable solution for connecting Kafka with external systems. Its flexibility, extensibility, and vast ecosystem of connectors make it the go-to tool for real-time data integration in modern data pipelines.
Understanding Kafka Connect
Kafka Connect is a powerful and scalable framework that enables the integration of external systems with Apache Kafka. It serves as a bridge between Kafka and other data sources or sinks, allowing for seamless data movement and synchronization.
At its core, Kafka Connect is built on top of the Kafka framework and leverages its distributed architecture, fault tolerance, and high throughput capabilities. It provides a simple and efficient way to connect external systems with Kafka, eliminating the need for custom connectors or complex data pipelines.
One of the key features of Kafka Connect is its ability to handle data integration in a fault-tolerant manner. It achieves this by providing automatic data recovery and error handling mechanisms. If a connector or a task fails, Kafka Connect can automatically restart it and resume data synchronization without any manual intervention.
Kafka Connect is designed to be scalable and can handle high volumes of data with ease. It supports parallelism by partitioning the data processing across multiple tasks, allowing for efficient utilization of resources. This makes it ideal for use cases where real-time data ingestion or large-scale data replication is required.
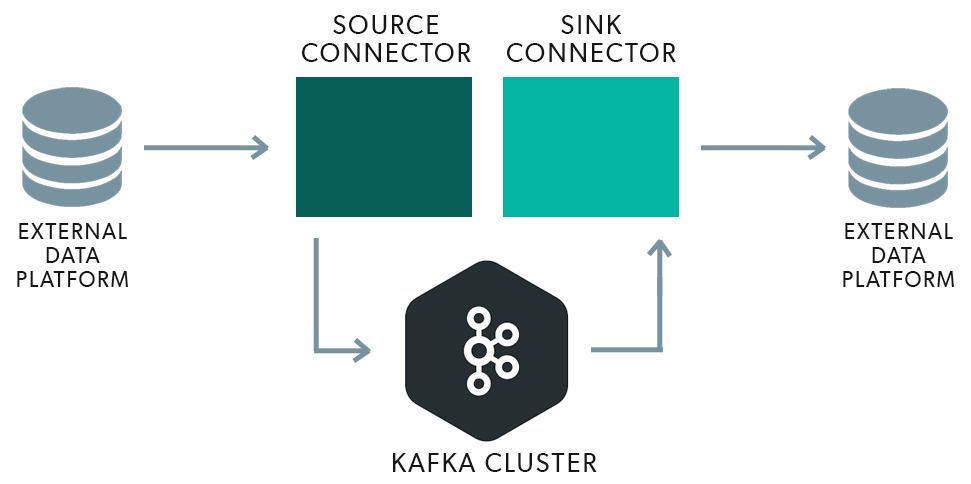
An important concept in Kafka Connect is the Connector. A Connector is responsible for defining the configuration and behavior of a data source or sink. It specifies the necessary settings, such as the connection details, transformation logic, and format serialization/deserialization, to enable seamless data integration.
Connectors in Kafka Connect can be categorized into two types: Source Connectors and Sink Connectors. Source Connectors enable the ingestion of data from external systems into Kafka, while Sink Connectors facilitate the export of data from Kafka to external systems.
With its flexible and extensible architecture, Kafka Connect supports a wide range of connectors out of the box. These connectors cover various data sources and sinks, including databases, Hadoop, cloud storage platforms, and messaging systems. Additionally, Kafka Connect offers a straightforward API for building custom connectors to integrate with proprietary or specialized systems.
Kafka Connect Connectors
In the ecosystem of Apache Kafka, Kafka Connect is a framework designed to simplify the integration of Kafka with external systems. It provides a scalable and flexible way to connect Kafka to different data sources and sinks, enabling seamless data ingestion and extraction.
Kafka Connect Connectors play a crucial role in this framework. They serve as the plugins or adapters that facilitate the communication between Kafka and external systems. Connectors are responsible for defining the logic to read data from source systems and write data to target systems.
Connectors are designed to be highly configurable, making it easy to customize the data pipeline according to specific requirements. They provide the flexibility to specify data formats, transformation logic, and the behavior of handling schema evolution.
Apache Kafka provides a rich set of connectors out of the box, known as “official connectors”. These connectors cover a wide range of use cases and make it simple to integrate Kafka with popular data sources and sinks.
Some of the commonly used Kafka Connect Connectors include:
- JDBC Connector: This connector allows you to connect Kafka to any relational database that supports JDBC, making it easy to ingest data from databases or write data to them.
- S3 Connector: With the S3 Connector, you can easily store data from Kafka directly into Amazon S3, enabling efficient and scalable data archiving or integration with other AWS services.
- Elasticsearch Connector: This connector enables seamless integration of Kafka with Elasticsearch, allowing data to be indexed and searchable in real-time.
- HDFS Connector: The HDFS Connector provides a way to write Kafka data to Hadoop Distributed File System (HDFS), enabling integration with the Hadoop ecosystem for data processing and analysis.
- Debezium Connector: This connector is specially designed for change data capture (CDC), allowing you to capture and stream database changes into Kafka topics. It supports a variety of databases, such as MySQL, PostgreSQL, and MongoDB.
These are just a few examples of the extensive range of connectors available for Kafka Connect. Whether you need to connect Kafka to a database, a message queue, a cloud storage service, or any other external system, there’s likely a Kafka Connect Connector that fits your needs.
Using Kafka Connect Connectors eliminates the need for custom code or complex integration processes, as they provide a standardized and reusable approach to connect Kafka with various systems. This simplifies the development and maintenance of Kafka-based data pipelines, saving time and effort.
Common Use Cases for Kafka Connect
Kafka Connect, as a highly scalable and fault-tolerant framework, offers a wide range of use cases for streaming data integration. Here are some common scenarios where Kafka Connect shines:
- Data ingestion from various sources: Kafka Connect allows you to easily and reliably ingest data from various sources, such as databases, messaging systems, log files, and more. Whether you need to capture real-time data updates or historical data, Kafka Connect provides connectors to seamlessly extract data from these sources and load it into Kafka topics.
- Stream processing and analytics: Kafka Connect integrates effortlessly with popular stream processing frameworks like Apache Spark, Apache Flink, and Apache Samza. By combining Kafka Connect with these frameworks, you can perform real-time analysis, transformations, aggregations, and enrichments on the data flowing through the Kafka topics. This enables you to gain valuable insights from the data as it streams through your system.
- Data integration between heterogeneous systems: Kafka Connect bridges the gap between different systems by providing connectors for connecting disparate technologies. Whether you need to integrate data between databases, cloud-based services, legacy systems, or any other systems, Kafka Connect simplifies the process by providing connectors that handle the complexities of data mapping and transformation.
- Database replication: Kafka Connect is an ideal solution for replicating data between databases. With its reliable connectors, you can easily replicate data from a primary database to one or more secondary databases, ensuring consistency and availability. This is particularly useful in scenarios where you need to keep multiple databases in sync, enable disaster recovery, or set up active-active database configurations.
- Data archival and retention: Kafka Connect makes it straightforward to archive and retain data. By leveraging connectors to storage systems like HDFS or cloud-based object stores, you can move data from Kafka topics to long-term storage for compliance, regulatory, or historical purposes. This allows you to offload data from Kafka while still retaining access to it when needed.
- Data integration with external services: Kafka Connect simplifies the integration of Kafka with external services, such as data warehouses, search engines, and online analytics platforms. With connectors available for popular services like Elasticsearch, Amazon S3, Google BigQuery, and more, you can seamlessly transfer data between Kafka and these services for further analysis, indexing, and reporting.
These are just a few examples of the common use cases for Kafka Connect. The flexibility and extensibility of Kafka Connect enable it to be a versatile tool for handling various data integration requirements in your organization.
Conclusion
In conclusion, Kafka Connectors are a vital component in the Kafka ecosystem that enables seamless integration between Kafka and other data sources or destinations. Whether you need to extract data from databases, ingest data from various systems, transform data in real-time, or synchronize data across multiple systems, Kafka Connectors provide the necessary functionality to achieve these tasks effortlessly.
With a wide range of pre-built connectors available for popular data sources and destinations, as well as the ability to create custom connectors, Kafka Connectors offer immense flexibility and scalability. The ease of configuration and scalability allows organizations to streamline their data integration pipelines and unlock the full potential of their data.
By leveraging Kafka Connectors, businesses can ensure reliable and efficient data flow, enabling real-time data analysis, decision-making, and actionable insights. The power of Kafka Connectors lies in its ability to simplify the process of integrating disparate data sources and systems, empowering organizations to harness the full potential of their data and drive innovation.
FAQs
1. What is a Kafka Connector?
A Kafka Connector is a plugin or extension that enables seamless integration between Apache Kafka and other data sources or sinks. It allows you to easily connect Kafka to external systems such as databases, messaging systems, cloud services, or even custom-built applications.
2. Why do I need a Kafka Connector?
Kafka Connectors simplify the process of building data pipelines, as they provide ready-made tools for efficiently importing and exporting data between Kafka topics and external systems. Instead of writing custom code, you can leverage existing connectors to easily stream data to or from Kafka, enabling real-time data processing and analytics.
3. How do Kafka Connectors work?
Kafka Connectors work by utilizing the Kafka Connect framework, which is built on top of the Kafka Streams API. Connectors are responsible for reading data from or writing data to external systems, and they use Kafka Connect’s predefined interface to accomplish this. The connectors are run as standalone processes or as distributed workers, depending on the deployment mode.
4. Are there different types of Kafka Connectors?
Yes, there are two types of Kafka Connectors: source connectors and sink connectors. Source connectors pull data from external systems and write it to Kafka topics, while sink connectors consume data from Kafka topics and write it to external systems. Source connectors enable you to ingest data into Kafka, while sink connectors allow you to export data from Kafka to other systems.
5. Can I build my own Kafka Connector?
Absolutely! Kafka Connect provides an API and framework for building custom connectors. If there isn’t an existing connector available for your desired integration, you can create your own by extending the base Connector class provided by Kafka Connect. Building a custom connector allows you to tailor the integration to your specific requirements and leverage the power of Kafka’s distributed messaging system.