
When working with machine learning algorithms in R, it is essential to split your data into separate training and testing sets. This is a vital step in ensuring the accuracy and reliability of your model. By separating your data, you can train your model on a portion of the dataset and then evaluate its performance on the remaining unseen data.
In this article, we will explore various methods and techniques to split train and test data in R. We will cover both simple random sampling and stratified sampling, along with their respective advantages and use cases. Whether you are a data scientist, analyst, or researcher, understanding how to perform this data splitting process is crucial for building robust and accurate machine learning models.
Inside This Article
- What is Train and Test Data
- Importance of Splitting Data
- Methods to Split Train and Test Data in R
- Conclusion
- FAQs
What is Train and Test Data
In the field of machine learning and data analysis, the terms “train data” and “test data” play a crucial role in model development and evaluation. Train data refers to the subset of data used to train or build a machine learning model, while test data is a separate subset used to evaluate the performance of the trained model.
The main idea behind using train and test data is to simulate real-world scenarios. By training the model on a particular dataset and then testing it on another unseen dataset, we can gain insights into how well the model performs on new, unseen data. This is important because the ultimate goal is for the model to make accurate predictions or provide meaningful insights when faced with real-world data.
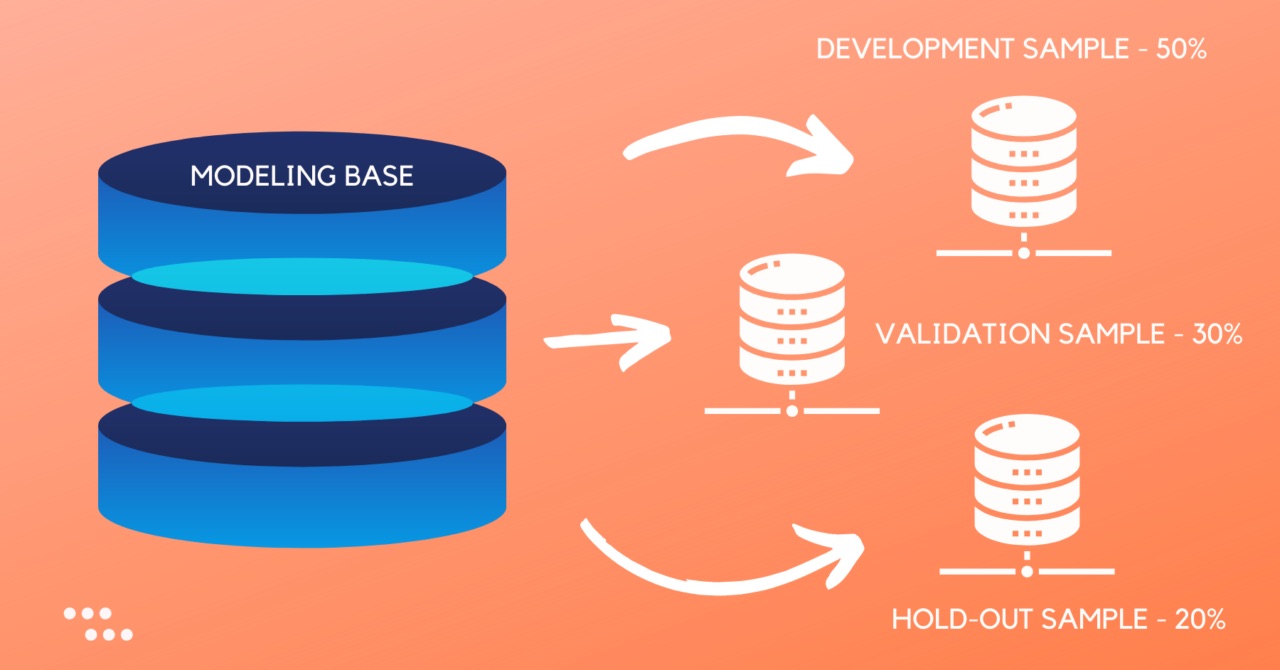
Typically, the train and test datasets are created by randomly dividing the available data into two parts. The train data is usually the larger portion, often around 70-80% of the entire dataset, while the remaining 20-30% is allocated to the test data. The train data is used to teach the model patterns and relationships between the input features and the target variable, while the test data is used to evaluate the model’s performance on unseen data.
Having separate train and test datasets is crucial for assessing how well a model generalizes to new, unseen data. If we were to evaluate the model’s performance on the same data used for training, it would give an overly optimistic view of the model’s capabilities. This is known as overfitting, where the model memorizes the training data instead of learning the underlying patterns and relationships.
By using separate test data, we can obtain a more realistic assessment of the model’s performance. If the model performs well on the test data, it indicates that it has successfully learned the patterns and can make accurate predictions even on unseen data. On the other hand, if the model performs poorly on the test data, it suggests that it may have overfit the training data or failed to capture the underlying patterns adequately.
Importance of Splitting Data
Data splitting is a crucial step in machine learning and data analysis. It involves dividing a dataset into two separate parts: the training set and the test set. The training set is used to train the model, while the test set is used to evaluate the performance of the trained model on unseen data.
Splitting the data into these two sets is important for several reasons. Firstly, it helps us assess how well our model will generalize to new, unseen data. If we evaluate the model on the same data it was trained on, it may give overly optimistic results and not perform well on new data. By using a separate test set, we can get a more accurate measure of how the model will perform in real-world scenarios.
Furthermore, data splitting allows us to detect and prevent overfitting. Overfitting occurs when a model becomes too complex and starts to memorize the training data rather than learning general patterns. By evaluating the model on an independent test set, we can identify if the model is overfitting and adjust it accordingly. This helps improve the model’s accuracy and reliability.
Splitting data is also important for model selection and hyperparameter tuning. During the training process, we may try different algorithms or adjust the parameters of the model to find the best combination. To accurately compare the performance of different models or parameter configurations, we need to use a separate test set.
Moreover, data splitting allows us to estimate the model’s performance and understand its limitations. By evaluating the model on unseen data, we can get insights into its strengths and weaknesses. This helps us gauge the reliability and applicability of the model in real-world scenarios.
Methods to Split Train and Test Data in R
When working with data in R, it is often necessary to split the data into two subsets: a training set and a test set. The training set is used to build the model, while the test set is used to evaluate its performance. In this article, we will explore various methods to split train and test data in R.
1. Random Sampling: One of the simplest and most common methods to split data is random sampling. This involves randomly selecting a certain percentage of the data as the training set and the remaining as the test set. The ‘caret‘ package in R provides the ‘createDataPartition()’ function, which makes this process straightforward.
2. Stratified Sampling: In some cases, it is important to maintain the class distribution in the training and test sets, especially when dealing with imbalanced data. Stratified sampling ensures that each class is represented in a similar proportion in both sets. The ‘caret’ package also offers the ‘createDataPartition()’ function with the ‘stratify’ argument to perform stratified sampling.
3. Time-based Split: For time series data, it is common to split the data based on a specific point in time. This can be done by setting a cutoff date and assigning all data before that date to the training set and the data after it to the test set.
4. Cross-Validation: Cross-validation is a technique that involves splitting the data into multiple subsets, or folds, and iteratively using each fold as the test set while the remaining folds are used as the training set. The ‘caret’ package provides the ‘createFolds()’ function to easily implement cross-validation in R.
5. Leave-One-Out Cross-Validation: Leave-One-Out Cross-Validation (LOOCV) is a special case of cross-validation where each data point acts as a test set, and the remaining data points are used as the training set. This method is particularly useful when dealing with small datasets.
6. Group-based Split: If the data has a grouping variable, such as individuals or geographical regions, it may be necessary to split the data based on those groups. This can be achieved using the ‘group_split()’ function from the ‘dplyr’ package in R.
7. 80/20 Split: The 80/20 split is a commonly used method where 80% of the data is assigned to the training set, and the remaining 20% is assigned to the test set. This split is often used when the dataset is large enough to provide sufficient training data.
These are some of the commonly used methods to split train and test data in R. The choice of method depends on the specific requirements of the project and the nature of the dataset. It is important to consider factors such as data distribution, sample size, and the presence of time series or grouping variables to determine the most appropriate method.
Conclusion
In conclusion, splitting your data into train and test sets is a crucial step in machine learning and data analysis using R. It allows you to assess the performance of your model on unseen data and make reliable predictions in real-world scenarios. By using the various functions and techniques available in R, such as the sample.split function or the caret package, you can easily create balanced and representative training and testing datasets.
Remember that the ratio at which you split your data depends on the size of your dataset and the specific requirements of your analysis. It is important to strike the right balance between having enough training data for model building and having enough testing data for evaluation.
By understanding how to split your data effectively, you can enhance the accuracy and reliability of your machine learning models, enabling you to make informed decisions and gain valuable insights from your data.
FAQs
Q: Why is splitting data into training and testing sets important in machine learning?
A: Splitting data into training and testing sets is crucial in machine learning to evaluate the performance of a model accurately. It helps in understanding how well the model generalizes to unseen data and prevents overfitting, where the model becomes overly specialized to the training data and performs poorly on new data.
Q: How can I split data into training and testing sets using R?
A: In R, you can use the createDataPartition() function from the caret package to split data into training and testing sets. This function randomly divides the data based on a specified percentage or ratio, ensuring a representative distribution of the data across both sets.
Q: What is the recommended ratio for splitting data into training and testing sets?
A: The recommended ratio for splitting data into training and testing sets depends on various factors, such as the size of the dataset and the complexity of the problem. A common practice is to use a 70:30 or 80:20 split, with 70% or 80% of the data allocated for training and the remaining percentage for testing. However, these ratios can vary based on the specific requirements of the project.
Q: Is there a way to ensure reproducibility when splitting data in R?
A: Yes, you can ensure reproducibility when splitting data in R by setting a random seed before performing the split. By setting a specific seed value, you can replicate the same randomization process, ensuring consistent and reproducible results across different runs of the code.
Q: Can I perform cross-validation instead of splitting data into training and testing sets?
A: Yes, instead of splitting data into training and testing sets, you can perform cross-validation in R. Cross-validation involves dividing the data into multiple subsets or folds and using each fold as a testing set while the remaining folds act as the training set. This approach provides a more robust estimate of the model’s performance by averaging the results across multiple iterations.